
基于whisper和Sakura-13B-Galgame的本地化生肉啃食教程(长多图警告)
写在前面

☆推荐文章☆
推荐理由:除了Gal,其他涩涩也可以用这个方案呢w
——小火
本教程是基于openAI公司开发的whisper开源语音识别模型(以下简称whisper)以及HuggingFace上的项目sakuraumi/Sakura-13B-Galgame模型(以下简称13B),以及基于以上这些模型开发的软件。这些软件或模型大多基于各类开源协议,并且提供了本地部署的方式。首先在此感谢各位软件开发者的工作。本文引用的软件都会标明出处,侵删。
本教程需要有一定的冲浪基础,部分教程不会说明或仅提供链接,烦请自行查看。
硬件需求/模型介绍
本次使用的两个大模型对显卡的显存有要求。whisper并没有明确指出是否必须使用N卡、A卡或I卡,并且显存需求不算大(即使是初代)。13B则是官方表示模型经过调试是可以在A卡上运行的,但官方并不提供A卡支持,并且显存占用较大。这两种模型均未提到是否对20系N卡及以上所搭载的专用AI单元有优化。
whisper是openAI(也就是开发了ChatGPT的那家公司)开发的开源语音识别模型,也具有一定的文字翻译能力。发布的时间较早,我当初是看BV15c411j789入坑的。当时我还在使用3050laptop 4G,使用medium模型以及large模型也不会因为显存容量小而导致出字幕的速度过慢,并且有成品软件(Buzz)提供了纯CPU计算的可能性,甚至是在Mac上也能运行。但初版的模型有不少缺陷,例如识别出了大量的语气词、时间一旦超过20分钟就会开始识别混乱几乎无法使用、翻译不稳定或者翻译连常规的机翻都不如。尽管如此也很优秀了。之后large版本的模型又迭代出了v2和v3两个版本。
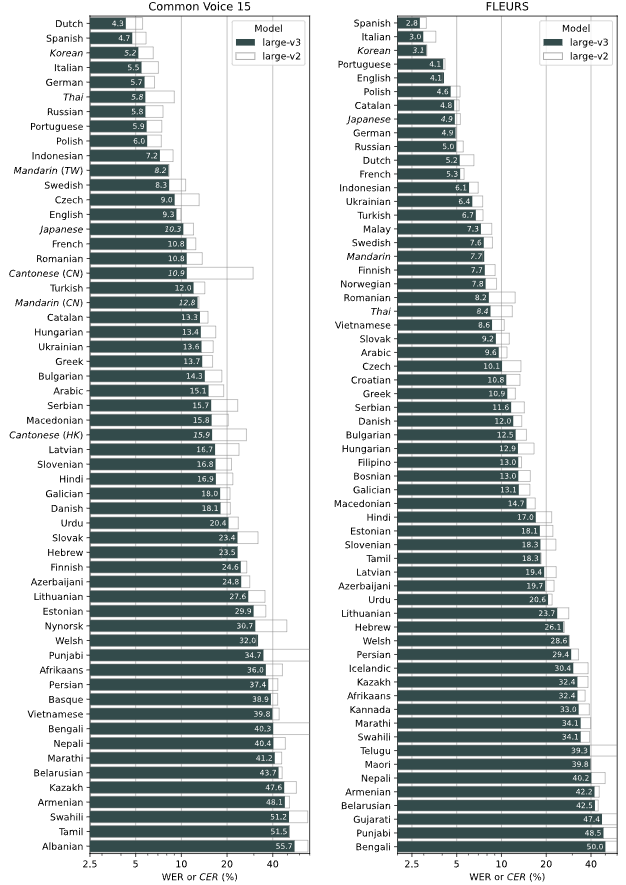
whisper之后出现了SYSTRAN/faster-whisper这个项目(以下简称faster)。faster不但做到了显存占用更小,还解决了上述whisper模型胡言乱语之类的问题,同时支持int8量化以实现更高的效率(其实主要是减小了显存占用和便于非N卡的情况下用CPU跑模型)。但相比faster模型相比whisper要求也更严苛,不但需要安装NVIDIA的CUDA套件,也更容易因为显存不足而爆显存。faster目前看来是更好用的,社区也基于faster衍生出了一些调整过后特化的模型(例如纯英语识别、日文转中文)。只要参数设置得当faster模型是又快又好的。就比如20系及以上的N卡因为专用AI单元的加入(计算卡请自行搜索是否有),半精度浮点性能提升很大,用float16跑AI能大幅提升运行速度。
13B是基于llama模型,通过喂了大量的galgame和轻小说数据集训练出来的,主要用于翻译轻小说。效果接近GPT3.5(原话:“目前仍为实验版本,v0.9版本模型在文风、流畅度与准确性上均强于GPT-3.5,但词汇量略逊于GPT-3.5(主观评价).”)。在经过多轮迭代之后目前迭代到了0.9b版本,并且提供了一键部署、租用/白嫖显卡部署等应用方式。但缺陷是太吃显存了,即使是int3或int2量化的模型版本也推荐12G显存的N卡。当然也可以租用/白嫖显卡或者卸载部分模型到CPU上(这可太好了,过于适合近几年高U低显的笔记本市场了)
接下来,本文将以 星期一的丰满 第一集 作为本次教程的素材(BV1ub411c74L P2)进行演示。
软件/模型准备
基于ffmepg的音视频处理软件(可选)
UVR5 人声分离(可选)
faster-whisper模型
NVIDIA CUDA套件
音视频转文字|字幕小工具(作者:B站@万能君的软件库)或 FasterWhisperGUI(作者:B站@UAreGoing2nd)
Subtitle Edit 字幕编辑器
Sakura-13B-Galgame模型
记事本等文本编辑器
第一步:提取音频文件(可选)、消除背景音(可选)
首先要做的事是把视频中的音频文件提取出来。这一步可以使用任何基于ffmepg的音视频处理软件。也可以不进行处理,以下使用到的两种音频转字幕软件都自带ffmepg,可以直接选中视频文件进行转写。
曾经进行字幕转写前比较重要的一件事是消除背景音。影片中的背景音乐会干扰模型的识别,尤其是whisper模型,甚至一段不含有任何语音的BGM都会干扰整体的识别(即使语音部分不再包含BGM)。但faster模型似乎对这一问题进行了完善(参考BV1Fj41197Vs),本次尝试不进行人声分离并进行语音识别。
如果你觉得BGM对识别有干扰或者是其他担心,也可以使用软件UVR进行人声分离。这是一个利用AI模型对音频进行人声分离的软件。教程上参考BV1ga411S7gP。在此不进行过多赘述。
第二步:安装NVIDIA CUDA套件
参考这篇CSDN教程。需要NVIDIA账号。下载cuda和cudnn(11.8版本)_cudnn下载-CSDN博客
第三步:语音转文字(faster-whisper)
第二步是重要的一步:使用基于faster-whisper模型进行转写(使用whisper模型参考这个教程BV15c411j789,largev2 v3同样适用)。使用到的软件是 音视频转文字|字幕小工具(作者:B站@万能君的软件库)或 FasterWhisperGUI(作者:B站@UAreGoing2nd)。前者易于使用,后者可调节的参数更多,并且集成了whisperX等一系列工具以提供更多诸如时间戳对齐等功能。本文将以音视频转文字|字幕小工具V1.2和FasterWhisperGUI 0.5.7为例,着重介绍几个重点参数(其余参数有兴趣可以去自行了解,或者抄别人)。FasterWhisperGUI的教程可以参考BV1oC4y1c7KF。
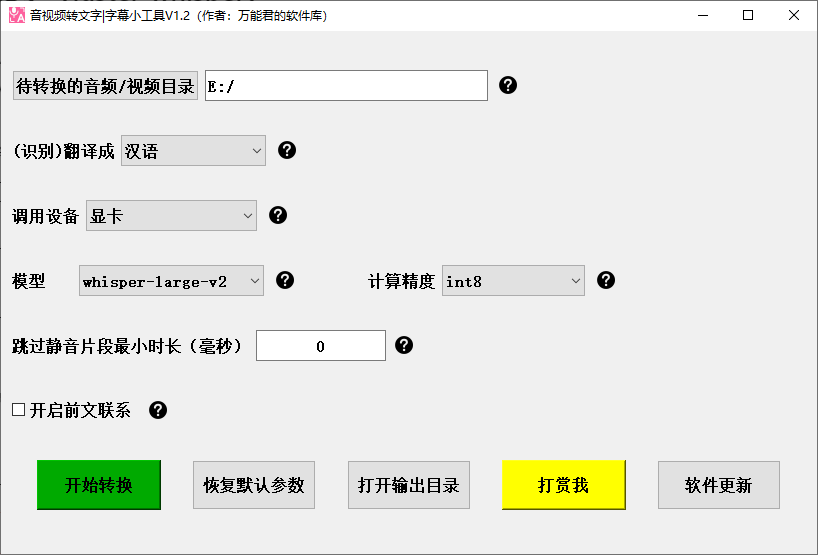
- (识别)翻译成:在这里设置音频的语言或希望将音频翻译为何种语言。如果选择的是需要翻译的语言,在第一版whisper模型中有概率不翻译并提示语言错误,V2V3就不存在这个问题了。但是翻译的真的很烂,如果没有其他很好的翻译手段不推荐用自带的翻译。当然也有好处,就是快,转完就能看。
- 模型:选择使用什么模型。具体可以将鼠标放置在旁边的“?”处查看V2和V3模型的利弊。图稳就选V2,V3感觉目前看还有些小bug。暂不支持自定义模型,需要用自定义模型的建议FasterWhisperGUI
- 调用设备:如果你的N卡显存大于3G就无脑选显卡吧,其他就选CPU。
- 计算精度:最重要的参数之一。在调用设备选择显卡的情况下,如果你的显卡是20系及以上,建议先尝试float16(20系之后加入的专用AI单元对半精度浮点支持很好)。盯紧随软件同时打开的控制台,如果跑着跑着爆显存了,那就试试其他的int8、float32之类的(bfloat16我暂时没搞明白,int8_float16感觉像是混合精度)。如果你用CPU跑,那就请直接选int8吧。同样可以将鼠标放置在旁边的“?”处查看作者的提示。
- 跳过静音片段最小时长:字面意思
- 开启前文联系:字面意思。但开启之后会导致重复翻译等问题。推荐不开,无视。
作者提供的软件包直接包含了faster V2和V3模型,不需要自行下载了。配置好以上参数之后,开始转换就行。如果软件的控制台显示爆显存了记得重新设置计算精度。会同时输出字幕和不带时间戳的文本文件。
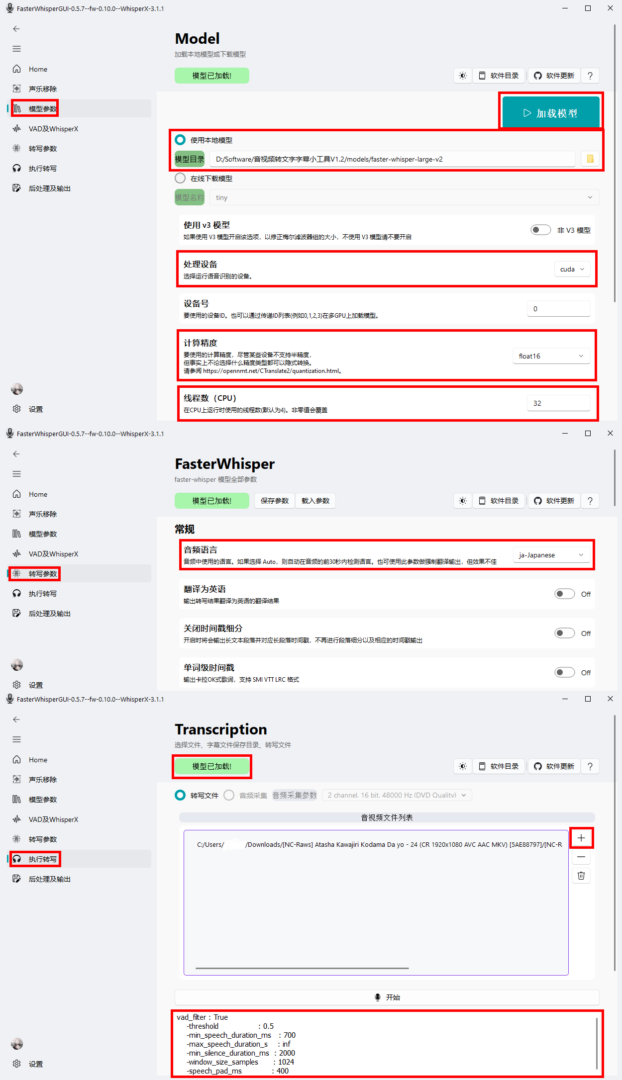
- FasterWhisperGUI不提供模型,需要自行去下载所需要的模型。链接贴在下面了,注意只能选择faster模型,whisper的gguf文件在此并不适用。选择本地模型后点击右上角的加载模型,当模型加载完成后会显示“模型已加载”,此时才可以进行转写。
- 处理设备:CUDA即显卡(N卡)
- 计算精度:同上
- 添加需要转写的文件,可以一次添加多个。执行后还是得盯一下下面的控制台,防止爆显存,同时便于后续调试计算精度。
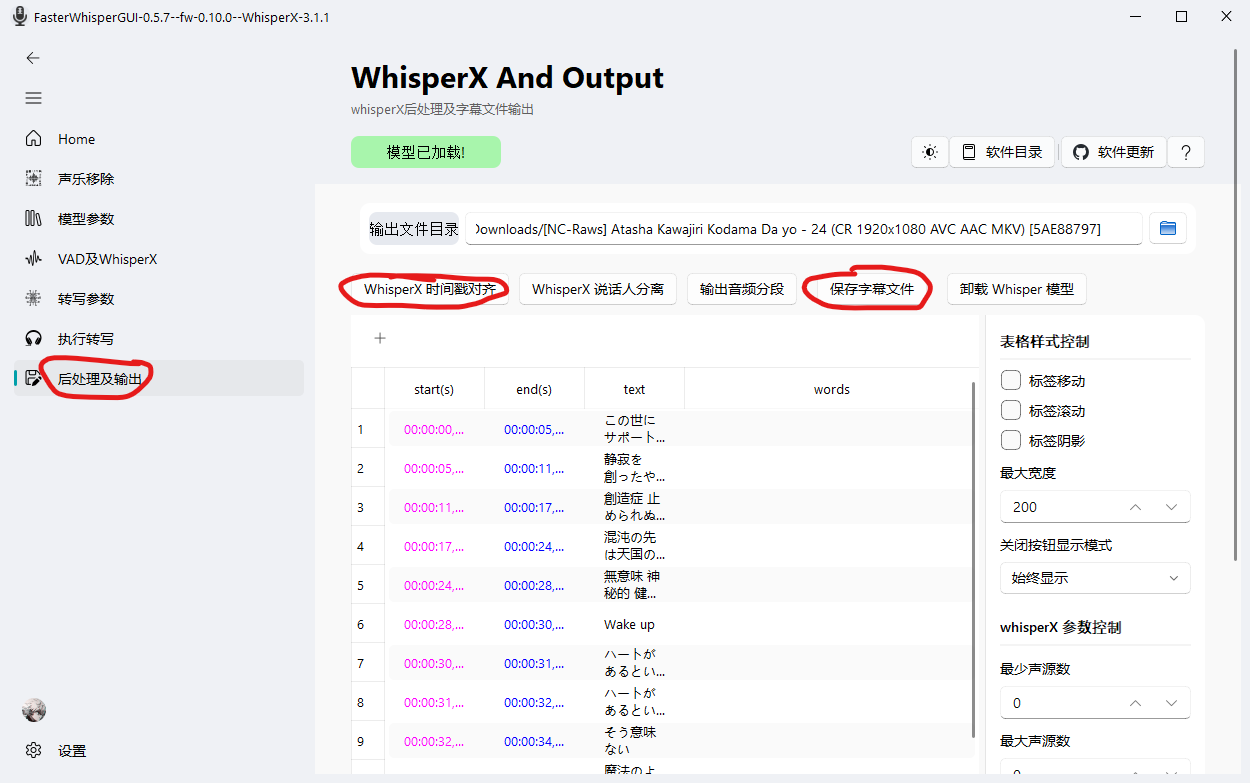
- 完成后在“后处理即输出”中导出字幕,如果觉得时间戳不准就对齐一下。
- 软件目前有bug,没法正常输出到音频目录或设置的目录。可以去软件根目录下的temp文件夹里面找到输出的字幕文件。
第四步:字幕处理(可选,但最好做一下)
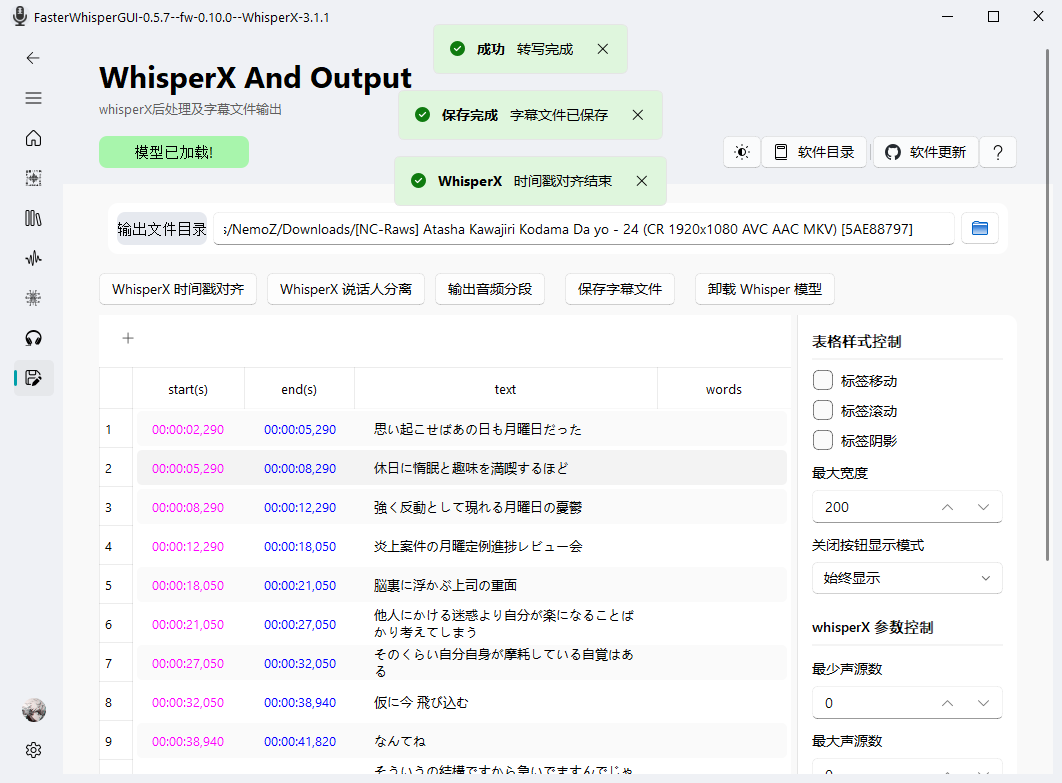
一段时间之后转写完成,字幕已经正常输出了,但是打开会发现挺乱的。主要是大量的语气词被识别、上下文重复、某段字幕特别长这几种情况。这时候最好是用SubtitleEdit处理一下,以减轻和加速后续的文本翻译。
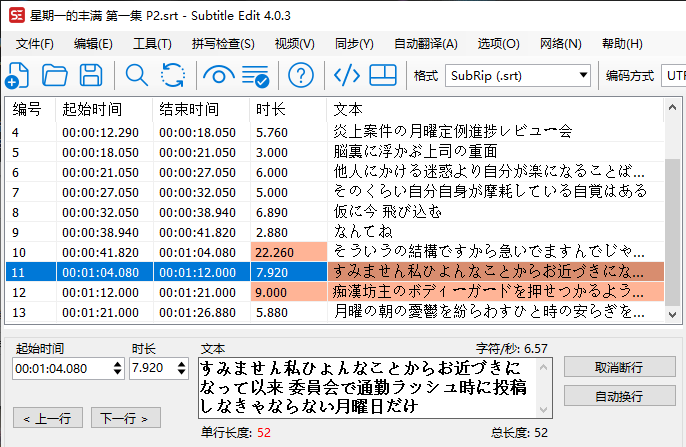
- 大量的语气词、重复词:建议直接删除,没必要留。如果想留的话建议只保留三到五个。
- 上下文重复:工具(T)->合并内容相同的行。会有漏掉的,可以手动选中多行,右键“合并所选行”
- 某段字幕特别长:工具(T)->分割长行,软件会根据标点自动帮你打上回车,但不会改变时间轴。或者带时间轴手动分割,前提是懂日语对照着视频进行分割,不然断句应该会很怪,但好处是能保持一段字幕文件稳定为6行
改完记得保存
第五步:字幕翻译(Sakura-13B-Galgame)
首先需要做的是把字幕文件的srt后缀改为txt后缀以供翻译识别。接着就是要部署13B模型。官方提供的教程:Sakura模型本地部署教程 (fishhawk.top) 写的很详细了,在这里只说几个要点:
- 13B模型的显存占用真的很大。用最新的0.9b 2bit量化,尽管这已经是最小的模型了,但如果不把部分模型卸载到CPU上,我的4060laptop的8G显存就会直接爆了。set ngl=32之后才好些,35都会爆。
- 官方提供了租用显卡和白嫖显卡的教程,显卡显存不够还是去搞云端算力吧。
第六步:翻译后的字幕处理(文本编辑器)
翻译后的字幕并非完美,仍存在着各种各样的问题。原字幕是这样的:
1
00:00:02,290 --> 00:00:05,290
思い起こせばあの日も月曜日だった如果选择“日中”翻译后的字幕是这样的:
1
1
00:00:02,290 --> 00:00:05,290
00:00:02,290 --> 00:00:05,290
思い起こせばあの日も月曜日だった
回想起来,那天也是星期一这样的字幕能被potplayer正常读取,但MXplayer就不行了。所以如果播放器不认识的话还得手动调整,最简单的办法就是删除多余的时间戳(具体删哪一行下面会说)。字幕编码不重要,不用管。
我采取的办法是三击选中整行(Notepad3)后回退删除。将鼠标滚轮设置为一次滚动6行,在没有两行字幕的情况下,可以直接把鼠标移到下一个时间轴的位置。建议写个脚本重复这一过程。
当然也可以选择“中文”,那样就会输出纯中文了:
1
00:00:02,290 --> 00:00:05,290
回想起来,那天也是星期一
目前还遇到两种偶发问题,举例说明:
2
2
00:00:05, 290 --> 00:00:08, 290
00:00:05,290 --> 00:00:08,290
休日に惰眠と趣味を満喫するほど
假日睡懒觉和享受兴趣
3
3
00:00:08,290 --> 00:00:12,290
00:00:08,290 --> 00:00:12,290
強く反動として現れる月曜日の憂鬱
星期一的强烈反作用力,出现忧郁症状
4
5
00:00:12,290 --> 00:00:18,050
00:00:12,290 --> 00:00:18,050
炎上案件の月曜定例進捗レビュー会
星期一的强烈反作用力,出现忧郁症状编码2的这种情况就应当删除“00:00:05, 290 –> 00:00:08, 290”的时间戳。以目前我使用的情况来看,中文和日文的排布完全是随机的。如果日文在后,那错误的时间戳就会出现在第二行,反之则出现在第一行。每份文本顺序固定。总之注意。
编码3和4这里会发现一段中文字幕重复了,编码4的字幕这里没有正常被翻译。这种情况就手动翻译一下吧,没什么好办法
编码4的4莫名其妙被翻译成了5,这种直接无视就行。
链接指路
音视频转文字|字幕小工具V1.2:https://www.bilibili.com/video/BV1d34y1F7qA
FasterWhisperGUI:CheshireCC/faster-whisper-GUI: faster_whisper GUI with PySide6 (github.com)
https://www.bilibili.com/read/cv25312969 https://www.bilibili.com/read/cv26636573
FasterWhisper模型:CheshireCC/faster-whisper-large-v3-float32 · Hugging Face
SubtitleEdit:SubtitleEdit/subtitleedit: the subtitle editor 🙂 (github.com)
Sakura-13B-Galgame项目:sakuraumi/Sakura-13B-Galgame · Hugging Face 在这里也可以查看显存需求以匹配合适的模型大小
Sakura模型本地部署教程:Sakura模型本地部署教程 (fishhawk.top) 写的很详细了
碎碎念
输出纯中文肯定是比输出中日两种语言混在一起方便,但就目前来看,还是有必要带上日文便于校对(那我为什么不打开原版进行校对呢,好蠢啊我)。
估计将来也能把语音识别的模型部署到云端。但目前whisper和faster本地跑着挺安逸,也就无所谓了,float16用不了大不了int8,int8的精度我是够用了。13B也能部署到云端。希望这俩模型越来越好吧。
来梦璃挺久了,一直想传点资源,但看公告感觉还是算了。我也没钱买资源,稍微分享一点折腾经验给有需求的人吧。不过这篇文章的排版肯定也是挺烂的了Orz
成果欣赏(大嘘)
1
00:00:02,290 --> 00:00:05,290
思い起こせばあの日も月曜日だった
回想起来,那天也是星期一
2
00:00:05,290 --> 00:00:08,290
休日に惰眠と趣味を満喫するほど
假日睡懒觉和享受兴趣
3
00:00:08,290 --> 00:00:12,290
強く反動として現れる月曜日の憂鬱
星期一的强烈反作用力,出现忧郁症状
4
00:00:12,290 --> 00:00:18,050
炎上案件の月曜定例進捗レビュー会
周一例会,讨论火烧屁股的案件
5
00:00:18,050 --> 00:00:21,050
脳裏に浮かぶ上司の重面
脑海浮现上司的严肃表情
6
00:00:21,050 --> 00:00:27,050
他人にかける迷惑より自分が楽になることばかり考えてしまう
比起给别人添麻烦,自己更想轻松一点
7
00:00:27,050 --> 00:00:32,050
そのくらい自分自身が摩耗している自覚はある
自觉到自己已经磨耗到这种程度
8
00:00:32,050 --> 00:00:38,940
仮に今 飛び込む
假如现在跳下去
9
00:00:38,940 --> 00:00:41,820
なんてね
开玩笑的
10
00:00:41,820 --> 00:01:04,080
そういうの結構ですから急いでますんでじゃあ 勝負でしたか大変ご迷惑をおかけしました
不用这么客气,我在赶时间,那么就一决胜负吧,给你添了大麻烦
11
00:01:04,080 --> 00:01:12,000
すみません私ひょんなことからお近づきになって以来
不好意思我从一个偶然的机会认识了她
委員会で通勤ラッシュ時に投稿しなきゃならない月曜日だけ
只有在委员会通勤高峰时间投稿的星期一
12
00:01:12,000 --> 00:01:21,000
痴漢坊主のボディーガードを押せつかるように
就像痴汉大坊的保镖一样
割れながら分不相応だと思うものこれも怪我の巧妙
虽然觉得不自量力但这也是受伤的巧妙
13
00:01:21,000 --> 00:01:26,880
月曜の朝の憂鬱を紛らわすひと時の安らぎを得た
得到了暂时的安宁来排解星期一早晨的忧郁